Author: Sunil Tiwari Date: 12-22-2025
Introduction
This blog documents a personal Security Operations Center (SOC) home lab project focused on building a privacy-first, AI-driven SOC using Wazuh and Llama 3.2, running natively on NVIDIA ARM64 infrastructure. This project was designed, deployed, and troubleshot end-to-end to translate academic cybersecurity knowledge into a practical, production-aligned environment.
During my academic journey in Cybersecurity Management, I worked on foundational projects such as Linux brute-force detection, packet analysis using Wireshark, and LAN troubleshooting. While these experiences strengthened my theoretical understanding, they offered limited exposure to real SOC operations, detection logic, and infrastructure constraints encountered in enterprise environments.
Through independent research and engagement with technical communities, I recognized that while certifications explain what security tools do, self-built labs teach how security operations actually function. This insight led me to design and implement a cybersecurity home lab using an NVIDIA DGX Spark platform.
Initial attempts to deploy traditional virtualized SOC environments were unsuccessful due to ARM64 compatibility and nested virtualization limitations. Rather than forcing an x86-centric approach, I intentionally pivoted to a native deployment model. This architectural decision eliminated virtualization overhead, reduced attack surface, and allowed full utilization of NVIDIA’s GPU-accelerated unified memory—a critical requirement for local AI inference.
The final lab architecture uses native and containerized services, including Wazuh for security monitoring, Ollama running Llama 3.2 for on-premise AI inference, and Python-based automation to support SOC workflows. While my primary focus is security engineering rather than software development, Python scripting enabled automated alert enrichment and analysis aligned with real SOC operations.
This blog outlines the architecture, design decisions, technical challenges, and lessons learned, demonstrating how on-premise AI can enhance SOC effectiveness without compromising data privacy.
Key Skills Demonstrated
- SOC Operations & Alert Triage
- Detection Engineering & Rule Correlation
- Linux System Administration (Ubuntu, ARM64)
- Package Management & Trust Repair (DPKG, APT, GPG)
- Wazuh SIEM (Manager, Indexer, Custom Rules)
- Credential Stuffing Detection
- Log Validation & Noise Reduction
- ARM64 Security Engineering
- Python Automation for SOC Workflows
- On-Premise AI Inference (Llama 3.2, Ollama)
- Privacy-First Security Architecture
ARM64 Infrastructure & the “Virtualization Wall”
Despite using high-performance hardware—the NVIDIA DGX Spark—the platform itself presented the first major challenge. While DGX Spark excels at AI workloads, its AARCH64 (ARM64) architecture is often unsupported or minimally addressed in traditional SOC lab tutorials designed for x86 systems.
Early attempts followed conventional lab designs using VirtualBox and KVM, but these approaches quickly failed due to nested virtualization performance degradation and architectural mismatches. Rather than treating this as a blocker, I reassessed the operational goal of the lab and chose a native, production-aligned deployment strategy.
By installing the Wazuh Manager and Indexer directly on the host operating system, I removed unnecessary abstraction layers and gained direct access to the system’s unified memory architecture. A Python virtual environment (.venv) was used to isolate automation dependencies while maintaining system stability. This design decision later proved critical for running Llama 3.2 efficiently on GPU without resource contention.
Linux Package Management & Trust Recovery
During installation, I encountered critical failures related to Wazuh repository signature verification. These issues stemmed from modern Ubuntu security changes and ARM64-specific repository behavior.
Manual GPG Key Restoration
Ubuntu 22.04 and later versions deprecate apt-key, and automated repository scripts occasionally fail on ARM64 systems. When the Wazuh repository returned a signature verification error, I manually restored trust by:
- Downloading the Wazuh public key directly using
curl - Converting the ASCII key to binary format using
gpg --dearmor - Storing the key in a dedicated keyring at
/usr/share/keyrings/wazuh.gpg - Explicitly binding the repository to this key in the
.listsource file
This approach followed modern Linux security best practices and ensured repository integrity.
Repairing a Locked DPKG Database
A failed installation attempt also left the DPKG database locked, preventing further package operations. To recover:
- Identified background processes holding the lock using
ps aux | grep apt - Attempted graceful termination of background updates
-
When the database remained locked:
- Manually removed stale
.lockand.lock-frontendfiles - Executed
sudo dpkg --configure -ato complete interrupted package operations
- Manually removed stale
This process stabilized the package manager and restored system consistency.
This phase reinforced a critical SOC principle: you cannot trust your security telemetry if you do not trust the underlying system producing it. Understanding Linux internals and package management is foundational to secure log collection and analysis.
Detection Engineering: The Logic Behind the Alerts
With the infrastructure stabilized, I moved into Detection Engineering, focusing on identifying Credential Stuffing behavior.
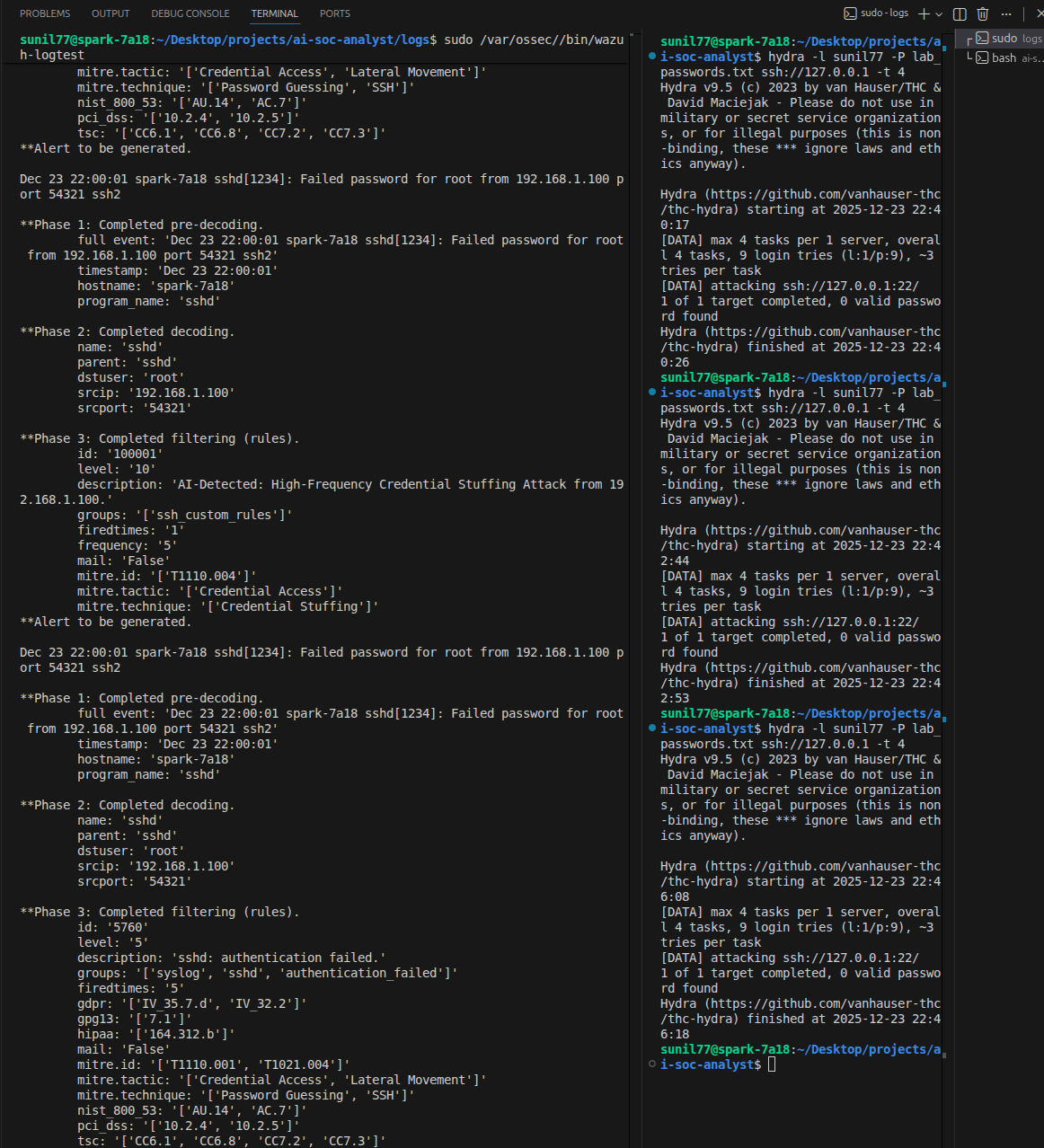
Initial custom detection rules failed to trigger as expected. Using wazuh-logtest, I identified that built-in Wazuh rules were evaluated before custom logic, preventing my rules from firing. Rather than duplicating detection logic, I re-engineered my approach to extend existing native rules.
By hooking into Rule 5760 (SSH authentication failure) and implementing stateful correlation, I defined a detection threshold of five failed authentication attempts within 60 seconds from the same source IP. Once exceeded, the event was escalated to a high-priority alert.
This approach ensured that alerts represented behavioral attack patterns, not isolated failures. The AI component was then able to focus on meaningful, aggregated events—reducing noise and aligning with real SOC triage workflows.
Closing Reflection
This project reflects my approach to security operations: understand the system, validate the logs, reduce noise, and detect behavior—not just alerts. By overcoming architectural limitations, repairing trust chains, and engineering meaningful detections, this lab mirrors challenges faced in real SOC environments.
Most importantly, it demonstrates how privacy-first, on-premise AI can support SOC analysts without exporting sensitive telemetry—an increasingly critical requirement in modern security operations.
The AI Analyst — Bridging Telemetry to Intelligence
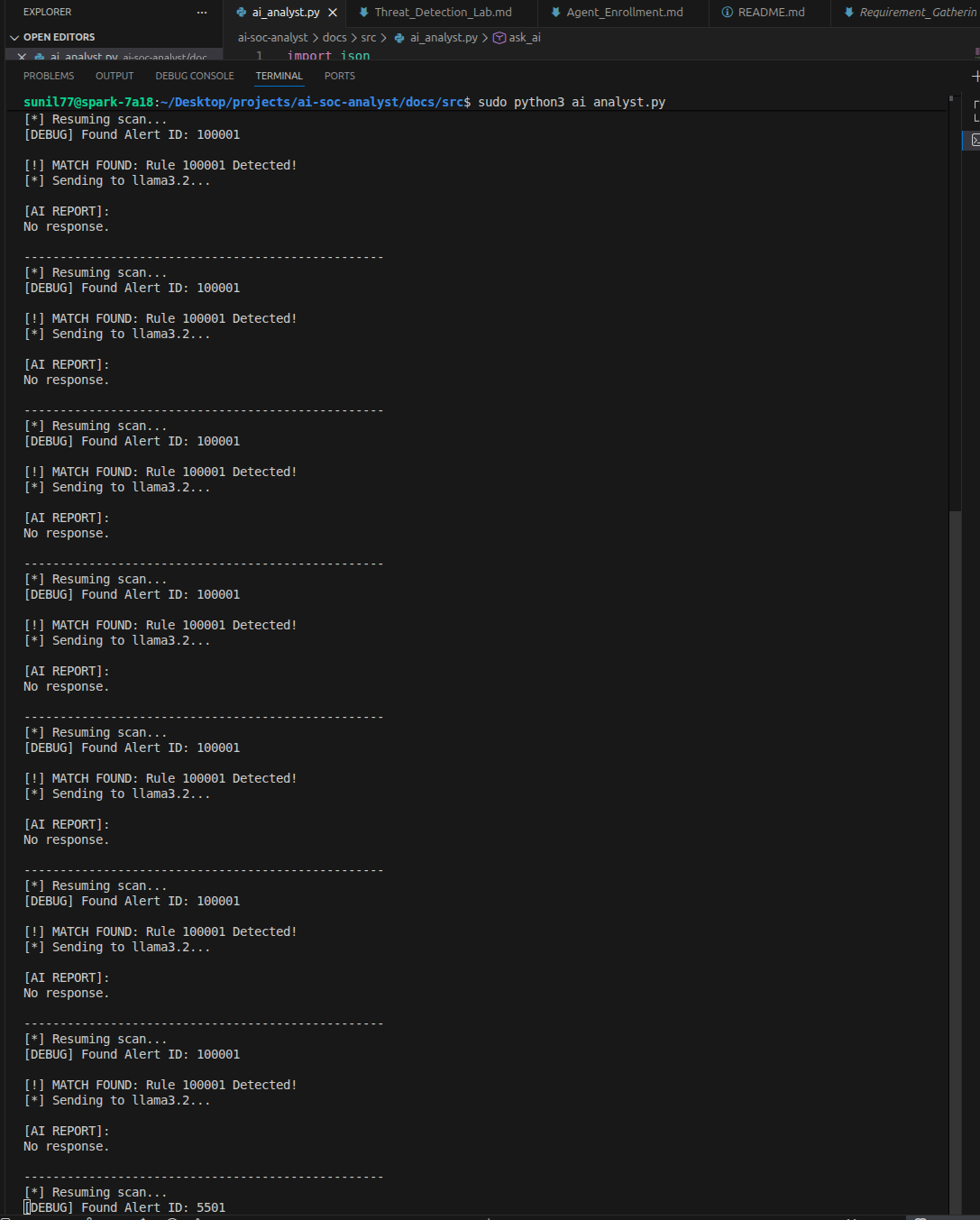
After completing detection engineering in Wazuh, the next challenge was making security telemetry actionable. To automate the “Who, What, and Where” of an attack, I developed a Python-based Telemetry Bridge that functions as a virtual Tier-1 SOC analyst—ingesting alerts, contextualizing events, and producing analyst-ready summaries in real time.
1. Engineering a Memory-Efficient Log Watcher
At the core of this automation is a Python script that continuously monitors the Wazuh alerts.json file. Because security logs can grow to gigabytes in size, loading the file into memory was not a viable option.
Instead, I implemented a generator-based log watcher using Python’s yield keyword.
-
The Logic:
By usingyield, the script remains in a paused state until a new log entry is written. This allows it to process events line by line without polling or re-reading the file. -
The Benefit:
This design enables real-time alert processing while maintaining a constant, minimal memory footprint. This was critical to ensure that the SIEM and the AI inference engine did not compete for RAM on the DGX Spark system.
This approach mirrors production SOC tooling, where efficiency and stability are just as important as detection accuracy.
2. Local Inference: Privacy by Design
When a high-severity alert (custom Rule ID 100001) is triggered, the script extracts relevant fields from the alert JSON and constructs a structured payload for the Ollama API.
Rather than relying on cloud-based AI services, I chose to run Llama 3.2 locally on NVIDIA hardware. This decision was driven by data sovereignty and operational security considerations:
-
Zero Data Exfiltration:
Sensitive telemetry—including internal IP addresses, usernames, and hostnames—never leaves the local environment. -
Low Latency:
By eliminating network calls to external APIs, the AI generates summaries and remediation guidance within milliseconds of detection.
This architecture demonstrates how AI can be safely integrated into SOC workflows without introducing new data exposure risks.
3. Turning Code into Conversation
The final output of the automation is a human-readable “Executive Brief.” Instead of presenting raw log entries, the AI interprets attack behavior and provides concise, actionable intelligence.
For example, during a Hydra-based brute-force attack, the system does not simply report repeated authentication failures. It:
- Identifies the attack pattern
- Attributes the source IP
- Summarizes the target and attack method
- Recommends immediate remediation actions, such as firewall blocking
This translation of telemetry into decision-ready context significantly reduces Mean Time to Respond (MTTR)—from minutes to seconds.
To ensure reliability during high-velocity attacks, I used json.loads(line) to convert raw log entries into Python dictionaries and accessed fields using .get() for safe navigation. This defensive coding approach prevents script failure if optional fields are missing, maintaining resilience under attack conditions.
Why This Matters in a SOC Environment
This AI-assisted workflow reflects real SOC priorities:
- Reduce alert fatigue
- Preserve analyst attention for high-risk events
- Maintain privacy and control over sensitive telemetry
- Accelerate response without sacrificing accuracy
Rather than replacing analysts, the system acts as a force multiplier, allowing human analysts to focus on validation and decision-making instead of manual triage.